


The financial industry continues to evolve rapidly with technological advancements reshaping how trading is conducted. At last week’s 25th Anniversary TradeTech Europe conference in Paris, industry experts shared valuable insights on how machine learning is transforming transaction cost analysis (TCA) and execution strategies.
This blog highlights the key takeaways from an enlightening discussion featuring Mark Montgomery, CCO from big xyt, and a senior execution trader from a leading European buy-side institution.
The Evolution of TCA: From Simple Metrics to Machine Learning
Traditional Trading Reinforcement Lifecycle
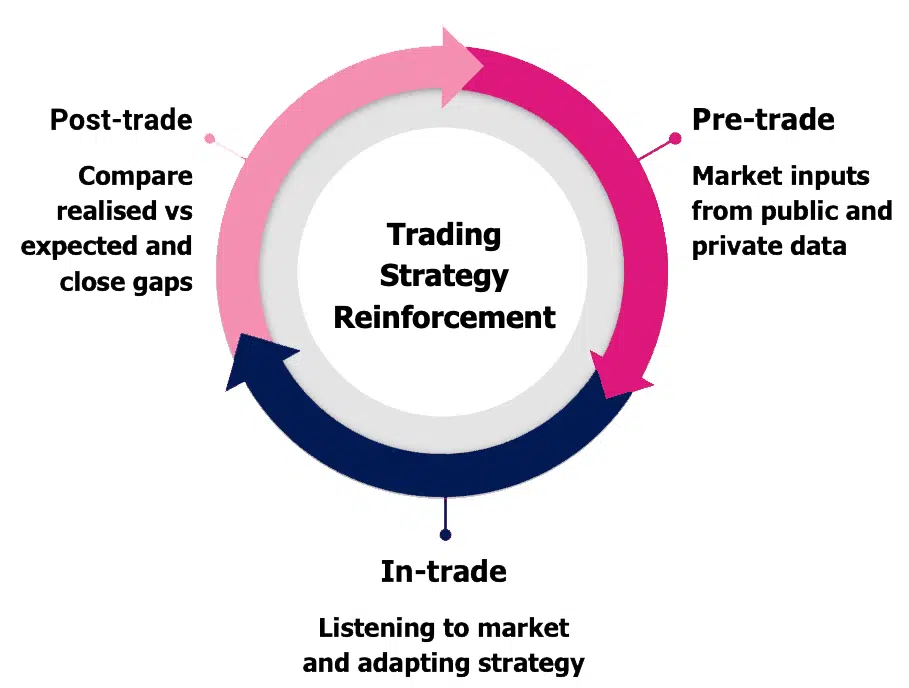 The traditional pre-trade, intra-trade and post-trade reinforcement cycle has been a cornerstone of trading enhancement for years. Mark from big xyt points out, this process has evolved significantly with the integration of machine learning techniques, taking optimisation to new levels of sophistication.
The traditional pre-trade, intra-trade and post-trade reinforcement cycle has been a cornerstone of trading enhancement for years. Mark from big xyt points out, this process has evolved significantly with the integration of machine learning techniques, taking optimisation to new levels of sophistication.
While traders have long been familiar with balancing single stock orders between market impact and opportunity cost, the challenge is amplified when dealing with large portfolios. The discussion revealed how clustering techniques are now replacing traditional market cap or country subdivisions.
Intelligent Clustering: Beyond Traditional Categories
Cluster Spread vs ADV
One of the most significant innovations highlighted was the use of advanced clustering techniques to identify patterns across securities with similar trading characteristics. Rather than simply categorising stocks by country or market cap, big xyt’s approach incorporates:
- Historical trading data and market characteristics
- Experiential data points from previous trades
- Trading mechanism performance across different venues
- Perceived venue toxicity including dark pool effectiveness
- Broker performance across various aggression levels
This multidimensional approach creates more meaningful groupings that can inform smarter execution decisions.
Real-World Automation: A Structured Path
An experienced trader shared insights into how their automation journey began in 2014, initially using static data such as average volume, spread and nominal trading instructions. Their collaboration with big xyt enhanced this automation through machine learning.
Their methodology follows a structured approach:
- Dividing the instrument universe by region and asset class
- Applying clustering based on multiple trading parameters
- Identifying the optimal number of clusters (typically 4-6)
- Integrating these clusters into their automated workflows
Cluster big xyt Dashboard
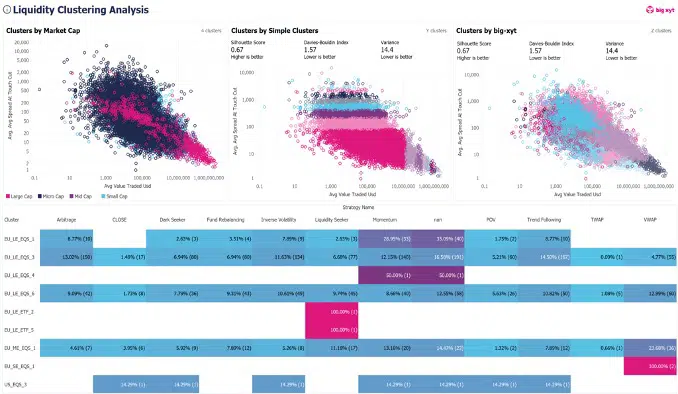
Key Trading Parameters for Clustering
The discussion revealed several critical parameters used in the clustering algorithm:
- Time to tick: The interval between price movements
- Time to trade: The interval between executed trades
- Size to ADTV: Trade size compared to average daily trading volume
These parameters help the machine learning algorithms using K-means to determine appropriate clusters that share similar trading characteristics.
Practical Applications and Benefits
Cluster big xyt Strategy Dashboard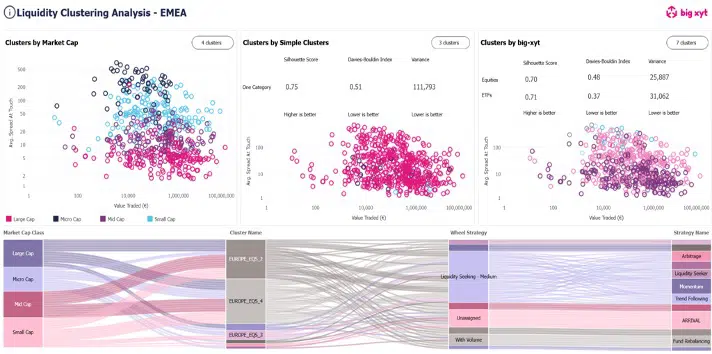
The real-world benefits of this approach were clearly articulated:
- Strategy Optimisation: Different clusters benefit from different algorithms. Highly liquid stocks (like Vodafone in “Cluster 1”) perform well with volume or liquidity-seeking algorithms, while instruments with infrequent trading require different approaches.
- Trader Support: Clusters are displayed to traders, helping them classify order difficulty even for manual executions, providing valuable additional context.
- Removal of Trader Bias: The clustering process eliminates preconceptions about how stocks should behave, allowing for data-driven decisions.
Implementation Challenges
The presenters didn’t shy away from discussing challenges:
- Compliance Requirements: Any algorithmic trading changes require validation from compliance departments.
- Cross-Department Buy-in: Success requires getting the whole desk on board, from high-touch to low-touch traders.
- Model Training Frequency: The model needs retraining (typically monthly) to account for changing market conditions, particularly during high volatility periods.
- Starting Small: Matthieu emphasised the importance of beginning with manageable ML projects and building incrementally.
Future Direction
Looking ahead, the speakers highlighted several areas for potential expansion:
- Incorporating addressable liquidity features into clusters
- Exploring applications beyond equities and ETFs into fixed income
- Adding features to determine optimal venue selection between dark pools and lit markets
- Enhancing models with full fragmentation and attribution data
Key Takeaway
The overarching message was clear: machine learning in trading requires a pragmatic approach. While these techniques offer powerful new capabilities, they must be implemented thoughtfully, with appropriate validation, reasonable training frequencies, and clean input data to avoid “garbage in, garbage out” scenarios.
As markets evolve, trading desks increasingly rely on transparent, consistent and granular market data to maintain a competitive edge in execution quality and cost efficiency. Our independent approach to data normalisation and market analytics – reinforced by our formal bid to deliver the EU Consolidated Tape – positions us to meet this growing demand, especially as machine learning models become integral to modern trading strategies.
This blog post is based on the discussion: Auto-Execution & TCA Case Study at TradeTech Europe, May 14, 2025.